The parser library is used in a similar way to Parsec which is a library for writing parsers in Haskell. It is based on higher-order parser combinators, so a complicated parser can be made out of many smaller ones.
This is a two stage process:
|
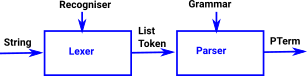 |
The advantage of using two stages, like this, is that things like whitespace and comments don't need to be considered in every parser rule.
The Idris parser library differs from Parsec in that you need to say in the Recogniser whether a rule is guaranteed to consume input. This means that the Idris type system prevents the construction of recognisers/rules that can't consume the input.
The Lexer is similar but works at the level of characters rather than tokens, and you need to provide a TokenMap which says how to build a token representation from a string when a rule is matched.
Test Code
Since this code is from Idris 2, I have adapted it to run under Idris 1:
mjb@localhost:~> cd Idris-dev/libs/algebra mjb@localhost:~/Idris-dev/libs/algebra> idris --clean algebra.ipkg Removed: outputFormat.ibc Removed: Core2.ibc Removed: Quantity2.ibc Removed: Lexer2.ibc Removed: ParserLexer2.ibc Removed: ParserCore2.ibc Removed: Parser2.ibc Removed: Support2.ibc Removed: IDEModeCommands2.ibc Removed: IDEModeParser2.ibc Removed: 00algebra-idx.ibc mjb@localhost:~/Idris-dev/libs/algebra> idris --build algebra.ipkg Type checking ./outputFormat.idr Type checking ./Core2.idr Type checking ./Quantity2.idr Type checking ./Lexer2.idr Type checking ./ParserLexer2.idr Type checking ./ParserCore2.idr Type checking ./Parser2.idr Type checking ./Support2.idr Type checking ./IDEModeCommands2.idr Type checking ./IDEModeParser2.idr mjb@localhost:~/Idris-dev/libs/algebra> idris --install algebra.ipkg Installing outputFormat.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing Core2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing Quantity2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing Lexer2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing ParserLexer2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing ParserCore2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing Parser2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing Support2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing IDEModeCommands2.ibc to /home/mjb/. cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra Installing IDEModeParser2.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/ idris-1.3.2/libs/algebra Installing 00algebra-idx.ibc to /home/mjb/.cabal/share/x86_64-linux-ghc-8.6.4/idris-1.3.2/libs/algebra mjb@localhost:~/Idris-dev/libs/algebra> idris -p algebra ____ __ _ / _/___/ /____(_)____ / // __ / ___/ / ___/ Version 1.3.2 _/ // /_/ / / / (__ ) http://www.idris-lang.org/ /___/\__,_/_/ /_/____/ Type :? for help Idris is free software with ABSOLUTELY NO WARRANTY. For details type :warranty. Idris> :module Core2 *Core2> :doc lex Core2.lex : TokenMap a -> String -> (List (TokenData a), Int, Int, String) Given a mapping from lexers to token generating functions (the TokenMap a) and an input string, return a list of recognised tokens, and the line, column, and remainder of the input at the first point in the string where there are no recognised tokens. The function is: Total & public export *Core2> |
You should now be able to run the examples:
Lexer

To lex some string to a list of tokens we define the structures using recognisers:

There are constructors and combinators to allow the construction of the lexer definition:
A simple recogniser is 'Pred' which uses a predicate (Char -> Bool) to test whether to accept the character. It can be constructed using the 'is' function: |
Idris> :module Lexer2 *Lexer2> is 'a' Pred (\ARG => intToBool (prim__eqChar ARG 'a')) : Recognise True |
Recognisers can be combined, for example,
<+> means sequence two recognisers. If either consumes a character, the sequence is guaranteed to consume a character. |
*Lexer2> is 'a' <+> is 'b'
SeqEat (Pred (\ARG => intToBool (prim__eqChar ARG 'a')))
(Delay (is 'b')) : Recognise True
*Lexer2>
|
<|> means if both consume, the combination is guaranteed to consumer a character: |
*Lexer2> is 'a' <|> is 'b'
Alt (Pred (\ARG => intToBool (prim__eqChar ARG 'a')))
(Pred (\ARG => intToBool (prim__eqChar ARG 'b'))) : Recognise True
*Lexer2>
|
Use of <+> and <|> allows more complicated lexers to be built up. Complex lexers can be split over many functions, for example, here is the lexer for Idris2 from src/Parser/Lexer.idr:
comment : Lexer
comment = is '-' <+> is '-' <+> many (isNot '\n')
toEndComment : (k : Nat) -> Recognise (k /= 0)
toEndComment Z = empty
toEndComment (S k)
= some (pred (\c => c /= '-' && c /= '{'))
<+> toEndComment (S k)
<|> is '{' <+> is '-' <+> toEndComment (S (S k))
<|> is '-' <+> is '}' <+> toEndComment k
<|> is '{' <+> toEndComment (S k)
<|> is '-' <+> toEndComment (S k)
blockComment : Lexer
blockComment = is '{' <+> is '-' <+> toEndComment 1
docComment : Lexer
docComment = is '|' <+> is '|' <+> is '|' <+> many (isNot '\n')
-- An identifier starts with alpha character followed by alpha-numeric
ident : Lexer
ident = pred startIdent <+> many (pred validIdent)
where
startIdent : Char -> Bool
startIdent '_' = True
startIdent x = isAlpha x
validIdent : Char -> Bool
validIdent '_' = True
validIdent '\'' = True
validIdent x = isAlphaNum x
holeIdent : Lexer
holeIdent = is '?' <+> ident
doubleLit : Lexer
doubleLit
= digits <+> is '.' <+> digits <+> opt
(is 'e' <+> opt (is '-' <|> is '+') <+> digits)
-- Do this as an entire token, because the contents will be processed by
-- a specific back end
cgDirective : Lexer
cgDirective
= exact "%cg" <+>
((some space <+>
some (pred isAlphaNum) <+> many space <+>
is '{' <+> many (isNot '}') <+>
is '}')
<|> many (isNot '\n'))
mkDirective : String -> Token
mkDirective str = CGDirective (trim (substr 3 (length str) str))
-- Reserved words
keywords : List String
keywords = ["data", "module", "where", "let", "in", "do", "record",
"auto", "implicit", "mutual", "namespace", "parameters",
"with", "impossible", "case", "of",
"if", "then", "else", "forall", "rewrite",
"using", "interface", "implementation", "open", "import",
"public", "export", "private",
"infixl", "infixr", "infix", "prefix",
"Type", "Int", "Integer", "String", "Char", "Double",
"total", "partial", "covering",
"Lazy", "Inf", "Delay", "Force"]
-- Reserved words for internal syntax
special : List String
special = ["%lam", "%pi", "%imppi", "%let"]
-- Special symbols - things which can't be a prefix of another symbol, and
-- don't match 'validSymbol'
export
symbols : List String
symbols
= [".(", -- for things such as Foo.Bar.(+)
"@{",
"(", ")", "{", "}", "[", "]", ",", ";", "_",
"`(", "`"]
export
opChars : String
opChars = ":!#$%&*+./<=>?@\\^|-~"
validSymbol : Lexer
validSymbol = some (oneOf opChars)
-- Valid symbols which have a special meaning so can't be operators
export
reservedSymbols : List String
reservedSymbols
= symbols ++
["%", "\\", ":", "=", "|", "|||", "<-", "->", "=>", "?", "&", "**", ".."]
|
So far, this is static code, to define the lexical structure. To lex a given text we need to pass this to the runtime code.
However this can only cut up the string into a list of substrings, these must be converted into tokens so we need a way to construct tokens. This will also depend on the lexical structure we require.
TokenMap
We then need to generate a TokenMap. This is a mapping from lexers to the tokens they produce.
This is a list of pairs:
(Lexer, String -> tokenType)
For each Lexer in the list, if a substring in the input matches, run
the associated function to produce a token of type `tokenType`
from Core2: TokenMap : (tokenType : Type) -> Type TokenMap tokenType = List (Lexer, String -> tokenType) |
Here is the code that generates the TokenMap for Idris2 lexer from src/Parser/Lexer.idr:
rawTokens : TokenMap Token
rawTokens =
[(comment, Comment),
(blockComment, Comment),
(docComment, DocComment),
(cgDirective, mkDirective),
(holeIdent, \x => HoleIdent (assert_total (strTail x)))] ++
map (\x => (exact x, Symbol)) symbols ++
[(doubleLit, \x => DoubleLit (cast x)),
(digits, \x => Literal (cast x)),
(stringLit, \x => StrLit (stripQuotes x)),
(charLit, \x => CharLit (stripQuotes x)),
(ident, \x => if x `elem` keywords then Keyword x else Ident x),
(space, Comment),
(validSymbol, Symbol),
(symbol, Unrecognised)]
where
stripQuotes : String -> String
-- ASSUMPTION! Only total because we know we're getting quoted strings.
stripQuotes = assert_total (strTail . reverse . strTail . reverse)
|
So, for our code, we can then turn this into a tokenMap by using a function like this:. |
myTokenMap : TokenMap Token |
We then call 'lex' (from Core),this gives a list of tokens with pointers to input string |
*MyParser> :doc lex
Core.lex : TokenMap a ->
String -> (List (TokenData a), Int, Int, String)
Given a mapping from lexers to token generating
functions (the TokenMap a) and an input string,
return a list of recognised tokens, and the line,
column, and remainder of the input at the first
point in the string where there are no recognised
tokens.
The function is: Total & export
Parser.Lexer.lex : String ->
Either (Int, Int, String) (List (TokenData Token))
The function is: Total & export |
We should then be able to lex a string to tokens. If it is successful it will generate a list of TokenData like this: |
Idris> :module Core2 *Core2> lex myTokenMap "a" ([MkToken 0 0 (CharLit "a")], 0, 1, "") : (List (TokenData Token), Int, Int, String) |
| TokenData is just an instance of a token together with a pointer to the String it comes from. | ||| A token, and the line and column where it was ||| in the input record TokenData a where constructor MkToken line : Int col : Int tok : a |
| If it is not successful it will generate an error message: | *Core2> lex myTokenMap "b"
([], 0, 0, "b") :
(List (TokenData Token), Int, Int, String)
|
Again, for a more complicated example, we can look at the lexer for Idris2 from src/Parser/Lexer.idr:
public export
data Token = Ident String
| HoleIdent String
| Literal Integer
| StrLit String
| CharLit String
| DoubleLit Double
| Symbol String
| Keyword String
| Unrecognised String
| Comment String
| DocComment String
| CGDirective String
| EndInput |
The reason for doing it this way is to separate generating the lexer from running the lexer. The TokenMap can be created in code and then called at runtime:
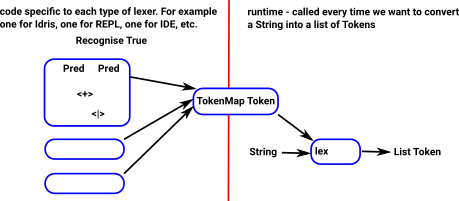
'Pred' is not the only recogniser. Here is the full data structure:
So far we have just looked at a trivially simple lexer, to create something more useful we need to combine simple recognisers to build up more complex recognisers.
Recognisers can be combined using <+> and <|> operators as follows:
<|> operator
| Alternative recognisers. If both consume, the combination is guaranteed to consumer a character. | (<|>) : Recognise c1 -> Recognise c2 -> Recognise (c1 && c2) (<|>) = Alt |
Examples
| This recognises optional characters: | ||| Recognise no input ||| (doesn't consume any input) empty : Recognise False empty = Empty ||| Recognise a lexer or recognise ||| no input. This is not guaranteed ||| to consume input. ||| /`l`?/ opt : (l : Lexer) -> Recognise False opt l = l <|> empty |
| This recognises a CR and LF together or on their own: | ||| Recognise a single newline sequence.
||| Understands CRLF, CR, and LF
||| /\\r\\n|[\\r\\n]/
newline : Lexer
newline = let crlf = "\r\n" in
exact crlf <|> oneOf crlf
|
<+> operator
Sequence two recognisers. If either consumes a character, the sequence is guaranteed to consume a character. If the first operand consumes the second operand can be infinite. |
(<+>) : {c1 : Bool} ->
Recognise c1 ->
inf c1 (Recognise c2) ->
Recognise (c1 || c2)
(<+>) {c1 = False} = SeqEmpty
(<+>) {c1 = True} = SeqEat |
Examples
This recognises a sequence like this: start <+> middle <+> end |
||| Recognise all input between `start` and `end` lexers.
||| Supports balanced nesting.
|||
||| For block comments that don't support
||| nesting (such as C-style comments),
||| use `surround`
blockComment : (start : Lexer) -> (end : Lexer) -> Lexer
blockComment start end = start <+> middle <+> end
where
middle : Recognise False
middle = manyUntil end (blockComment start end <|> any) |
another example
| This recognises a sequence of digits which may optionally have a minus sign at the start: | ||| Recognise a single digit 0-9 ||| /[0-9]/ digit : Lexer digit = pred isDigit |
Since Idris is eager by default it would try to eagerly evaluate all branches. If combinators are recursive then they need to occur in a lazy context, hence use of Inf in <+>.
For example, the code to recognise an identifier requires an alphabetic character followed by any number of alpha-numeric characters. This is implemented by 'many', which requires recursion, and so <+> needs to handle infinite data. |
ident : Lexer
ident = pred startIdent <+> many (pred validIdent)
where
startIdent : Char -> Bool
startIdent '_' = True
startIdent x = isAlpha x
validIdent : Char -> Bool
validIdent '_' = True
validIdent '\'' = True
validIdent x = isAlphaNum x |
Lexer Code
Given a TokenMap and an input String we can create a list of Tokens.
This is done here: Idris2/src/Text/Lexer/Core.idr
||| Given a mapping from lexers to token generating functions (the
||| TokenMap a) and an input string, return a list of recognised tokens,
||| and the line, column, and remainder of the input at the first point in the
||| string where there are no recognised tokens.
export
lex : TokenMap a -> String -> (List (TokenData a), (Int, Int, String))
lex tmap str
= let (ts, (l, c, str')) = tokenise (const False) 0 0 [] tmap (mkStr str) in
(ts, (l, c, getString str'))
|
The TokenMap is a mapping from lexers to the tokens they produce. This is a list of pairs `(Lexer, String -> tokenType)` For each Lexer in the list, if a substring in the input matches, run the associated function to produce a token of type `tokenType`
||| A mapping from lexers to the tokens they produce. ||| This is a list of pairs `(Lexer, String -> tokenType)` ||| For each Lexer in the list, if a substring in the input matches, run ||| the associated function to produce a token of type `tokenType` public export TokenMap : (tokenType : Type) -> Type TokenMap tokenType = List (Lexer, String -> tokenType) |
The TokenMap depends on the language being lexed, for Idris2 it is defined in src/Parser/Lexer.idr rawTokens:
export
rawTokens : TokenMap Token
rawTokens =
[(comment, Comment),
(blockComment, Comment),
(docComment, DocComment),
(cgDirective, mkDirective),
(holeIdent, \x => HoleIdent (assert_total (strTail x)))] ++
map (\x => (exact x, Symbol)) symbols ++
[(doubleLit, \x => DoubleLit (cast x)),
(digits, \x => Literal (cast x)),
(stringLit, \x => StrLit (stripQuotes x)),
(charLit, \x => CharLit (stripQuotes x)),
-- An identifier starts with alpha character followed by alpha-numeric
(ident, \x => if x `elem` keywords then Keyword x else Ident x),
(space, Comment),
(validSymbol, Symbol),
(symbol, Unrecognised)]
where
stripQuotes : String -> String
-- ASSUMPTION! Only total because we know we're getting quoted strings.
stripQuotes = assert_total (strTail . reverse . strTail . reverse)
|
So we can try running the lexer with an input string of "test 3 " like this:
*MyParser> lex rawTokens "test 3" ([MkToken 0 0 (Ident "test"), MkToken 0 4 (Comment " "), MkToken 0 5 (Literal 3)], 0, 6, "") : (List (TokenData Token), Int, Int, String) *MyParser> |
Note: in order for this to displayed properly I needed to change calls to fspan in Core.idr into the standard span function otherwise it displays lazy code to produce the output rather than the output itself.
We can see from the example above that the input string "test 3" gives the following sequence of tokens:
- Ident "test"
- Comment " "
- Literal 3
Token
Idris2/src/Parser/Lexer.idr
public export
data Token = Ident String
| HoleIdent String
| Literal Integer
| StrLit String
| CharLit String
| DoubleLit Double
| Symbol String
| Keyword String
| Unrecognised String
| Comment String
| DocComment String
| CGDirective String
| EndInput
also here:
Idris2/src/Text/Token.idr
||| A token of a particular kind and the text that was recognised. record Token k where constructor Tok kind : k text : String
TokenMap
Idris2/src/Text/Lexer/Core.idr
||| A mapping from lexers to the tokens they produce. ||| This is a list of pairs `(Lexer, String -> tokenType)` ||| For each Lexer in the list, if a substring in the input matches, run ||| the associated function to produce a token of type `tokenType` public export TokenMap : (tokenType : Type) -> Type TokenMap tokenType = List (Lexer, String -> tokenType)

Idris2/src/Text/Lexer/Core.idr
tokenise : (TokenData a -> Bool) ->
(line : Int) -> (col : Int) ->
List (TokenData a) -> TokenMap a ->
StrLen -> (List (TokenData a), (Int, Int, StrLen))
tokenise pred line col acc tmap str
= case getFirstToken tmap str of
Just (tok, line', col', rest) =>
-- assert total because getFirstToken must consume something
if pred tok
then (reverse acc, (line, col, MkStrLen "" 0))
else assert_total (tokenise pred line' col' (tok :: acc) tmap rest)
Nothing => (reverse acc, (line, col, str))
where
countNLs : List Char -> Nat
countNLs str = List.length (filter (== '\n') str)
getCols : String -> Int -> Int
getCols x c
= case fspan (/= '\n') (reverse x) of
(incol, "") => c + cast (length incol)
(incol, _) => cast (length incol)
getFirstToken : TokenMap a -> StrLen -> Maybe (TokenData a, Int, Int, StrLen)
getFirstToken [] str = Nothing
getFirstToken ((lex, fn) :: ts) str
= case takeToken lex str of
Just (tok, rest) => Just (MkToken line col (fn tok),
line + cast (countNLs (unpack tok)),
getCols tok col, rest)
Nothing => getFirstToken ts str |
this uses:
-- If the string is recognised, returns the index at which the token
-- ends
scan : Recognise c -> Nat -> StrLen -> Maybe Nat
scan Empty idx str = pure idx
scan Fail idx str = Nothing
scan (Lookahead positive r) idx str
= if isJust (scan r idx str) == positive
then Just idx
else Nothing
scan (Pred f) idx (MkStrLen str len)
= if cast {to = Integer} idx >= cast len
then Nothing
else if f (assert_total (prim__strIndex str (cast idx)))
then Just (idx + 1)
else Nothing
scan (SeqEat r1 r2) idx str
= do idx' <- scan r1 idx str
-- TODO: Can we prove totality instead by showing idx has increased?
assert_total (scan r2 idx' str)
scan (SeqEmpty r1 r2) idx str
= do idx' <- scan r1 idx str
scan r2 idx' str
scan (Alt r1 r2) idx str
= maybe (scan r2 idx str) Just (scan r1 idx str)
takeToken : Lexer -> StrLen -> Maybe (String, StrLen)
takeToken lex str
= do i <- scan lex 0 str -- i must be > 0 if successful
pure (substr 0 i (getString str), strTail i str) |
example of use:
| Here is an example using 'digits' which is a lexer that regognises numeric digits. | *MyParser> takeToken digits (mkStr "23 test")
Just ("23", MkStrLen " test" 5) : Maybe (String, StrLen)
*MyParser> takeToken digits (mkStr "test 23")
Nothing : Maybe (String, StrLen)
*MyParser> |
In src/Parser/Lexer.idr we have:
lexTo : (TokenData Token -> Bool) ->
String -> Either (Int, Int, String) (List (TokenData Token))
lexTo pred str
= case lexTo pred rawTokens str of
-- Add the EndInput token so that we'll have a line and column
-- number to read when storing spans in the file
(tok, (l, c, "")) => Right (filter notComment tok ++
[MkToken l c EndInput])
(_, fail) => Left fail
where
notComment : TokenData Token -> Bool
notComment t = case tok t of
Comment _ => False
DocComment _ => False -- TODO!
_ => True |
Idris2/src/Text/Lexer/Core.idr
lexTo : (TokenData a -> Bool) ->
TokenMap a -> String -> (List (TokenData a), (Int, Int, String))
lexTo pred tmap str
= let (ts, (l, c, str')) = tokenise pred 0 0 [] tmap (mkStr str) in
(ts, (l, c, getString str')) |
Top level view
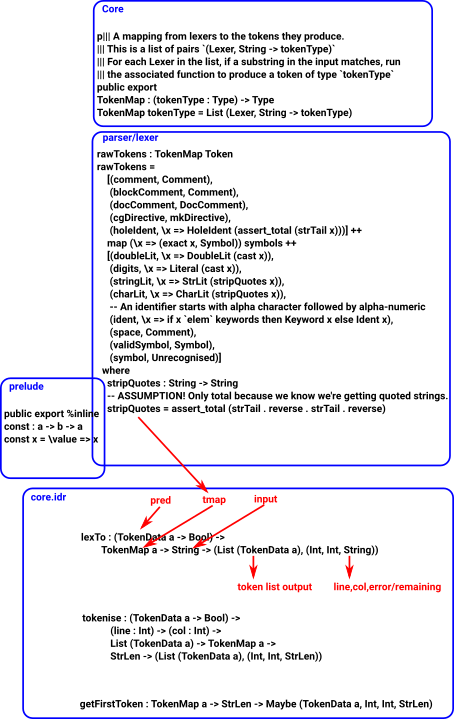
Why we need Inf in 'Recognise' and <+>
Take example of an arithmatic expression, we might have an addition operator:
a + b
but 'a' might itself be an expression containig an addition and so on to any debth. If we are rpresenting this in BNF-like form it might look like this:
expression ::= expression + expression
which requires lazy evaluation.
Parser
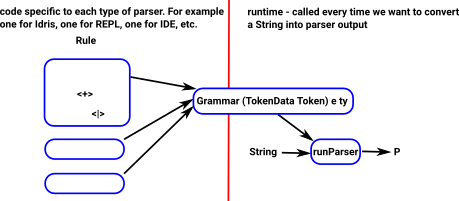
The laguage we are parsing is defined by a grammar.
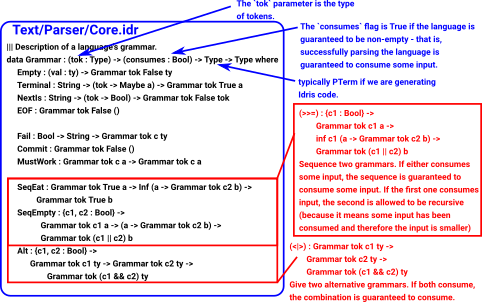
| Our grammar is defined by this data structure: | ||| Description of a language's grammar. The `tok` parameter is the type
||| of tokens, and the `consumes` flag is True if the language is guaranteed
||| to be non-empty - that is, successfully parsing the language is guaranteed
||| to consume some input.
public export
data Grammar : (tok : Type) -> (consumes : Bool) -> Type -> Type where
Empty : (val : ty) -> Grammar tok False ty
Terminal : String -> (tok -> Maybe a) -> Grammar tok True a
NextIs : String -> (tok -> Bool) -> Grammar tok False tok
EOF : Grammar tok False ()
Fail : Bool -> String -> Grammar tok c ty
Commit : Grammar tok False ()
MustWork : Grammar tok c a -> Grammar tok c a
SeqEat : Grammar tok True a -> Inf (a -> Grammar tok c2 b) ->
Grammar tok True b
SeqEmpty : {c1, c2 : Bool} ->
Grammar tok c1 a -> (a -> Grammar tok c2 b) ->
Grammar tok (c1 || c2) b
Alt : {c1, c2 : Bool} ->
Grammar tok c1 ty -> Grammar tok c2 ty ->
Grammar tok (c1 && c2) ty
|
We can construct simple grammar elements and then combine them in more complicated ways. (In a similar way to combining the recognisers in the lexer)
First we need a function of type: (tok -> Maybe a) |
myTokenPred : Token -> Maybe String myTokenPred t = Just "a" |
| Then we can construct a simple grammar element: | *MyParser> Terminal "a" myTokenPred Terminal "a" myTokenPred : Grammar Token True String |
There are some functions in Idris2/src/Parser/Support.idr that construct grammars. For example: 'intLit' recognises a number. |
*MyParser> Support2.intLit
Terminal "Expected integer literal"
(\x =>
case tok x of
Literal i => Just i
x => Nothing) :
Grammar (TokenData Token) True Integer |
| If we parse a grammar containig only intLit. It succeeds with "1" but fails with "a". | *MyParser> runParser "1" Support2.intLit Right 1 : Either ParseError Integer *MyParser> runParser "a" Support2.intLit Left (ParseFail "Expected integer literal" (Just (0, 0)) [Ident "a", EndInput]) : Either ParseError Integer |
| There are more built in elements of grammar. | *MyParser> constant
Terminal "Expected constant"
(\x =>
case tok x of
Literal i => Just (BI i)
StrLit s => case escape s of
Nothing => Nothing
Just s' => Just (Str s')
CharLit c => case getCharLit c of
Nothing => Nothing
Just c' => Just (Ch c')
DoubleLit d => Just (Db d)
Keyword "Int" => Just IntType
Keyword "Integer" => Just IntegerType
Keyword "String" => Just StringType
Keyword "Char" => Just CharType
Keyword "Double" => Just DoubleType
x => Nothing) :
Grammar (TokenData Token) True Constant
|
*MyParser> symbol "a"
Terminal "Expected 'a'"
(\x =>
case tok x of
Symbol s => if s == req
then Just ()
else Nothing
req => Nothing)
: Grammar (TokenData Token) True () |
|
*MyParser> strLit
Terminal "Expected string literal"
(\x =>
case tok x of
StrLit s => Just s
x => Nothing) :
Grammar (TokenData Token) True String
|
|
*MyParser> keyword "data"
Terminal "Expected 'data'"
(\x =>
case tok x of
Keyword s => if s == req
then Just ()
else Nothing
req => Nothing) :
Grammar (TokenData Token) True ()
|
|
*MyParser> operator
Terminal "Expected operator"
(\x =>
case tok x of
Symbol s => if elem s reservedSymbols
then Nothing
else Just s
x => Nothing)
: Grammar (TokenData Token) True String |
|
*MyParser> runParser "Int" (keyword "Int") Right () : Either ParseError () *MyParser> runParser "Hello" (keyword "Int") Left (ParseFail "Expected 'Int'" (Just (0, 0)) [Ident "Hello", EndInput]) : Either ParseError () |
|
| I'm not quite sure why 'symbol' always fails? | *MyParser> runParser "a" (symbol "a") Left (ParseFail "Expected 'a'" (Just (0, 0)) [Ident "a", EndInput]) : Either ParseError () *MyParser> runParser "a" (symbol "b") Left (ParseFail "Expected 'b'" (Just (0, 0)) [Ident "a", EndInput]) : Either ParseError () |
Example of use: see here.
We can now combine these simple grammars using >>= and <|> to build more complicated grammars.
When the grammar uses (TokenData Token) then we can just use 'Rule' as a simpler type. |
public export Rule : Type -> Type Rule ty = Grammar (TokenData Token) True ty |
Other parser combinators : |
||| Sequence a grammar with value type `a -> b` and a grammar
||| with value type `a`. If both succeed, apply the function
||| from the first grammar to the value from the second grammar.
||| Guaranteed to consume if either grammar consumes.
export
(<*>) : Grammar tok c1 (a -> b) ->
Grammar tok c2 a ->
Grammar tok (c1 || c2) b
(<*>) x y = SeqEmpty x (\f => map f y)
||| Sequence two grammars. If both succeed, use the value of the first one.
||| Guaranteed to consume if either grammar consumes.
export
(<*) : Grammar tok c1 a ->
Grammar tok c2 b ->
Grammar tok (c1 || c2) a
(<*) x y = map const x <*> y
||| Sequence two grammars. If both succeed, use the value of the second one.
||| Guaranteed to consume if either grammar consumes.
export
(*>) : Grammar tok c1 a ->
Grammar tok c2 b ->
Grammar tok (c1 || c2) b
(*>) x y = map (const id) x <*> y |
Parser Runtime
At runtime the function 'runParser' in Idris2/src/Parser/Support.idr gets called.
runParserTo : (TokenData Token -> Bool) ->
String -> Grammar (TokenData Token) e ty -> Either ParseError ty
runParserTo pred str p
= case lexTo pred str of
Left err => Left $ LexFail err
Right toks =>
case parse p toks of
Left (Error err []) =>
Left $ ParseFail err Nothing []
Left (Error err (t :: ts)) =>
Left $ ParseFail err (Just (line t, col t))
(map tok (t :: ts))
Right (val, _) => Right val
export
runParser : String -> Grammar (TokenData Token) e ty -> Either ParseError ty
runParser = runParserTo (const False) |
This uses 'lexTo' to convert the string into tokens.
There are different lexers depending on what language we are parsing. |
*MyParser> :doc lexTo
Core.lexTo : (TokenData a -> Bool) ->
TokenMap a -> String -> (List (TokenData a), Int, Int, String)
The function is: Total & export
Parser.Lexer.lexTo : (TokenData Token -> Bool) ->
String -> Either (Int, Int, String) (List (TokenData Token)) |
Yaffle
see Idris2/src/Yaffle/REPL.idr - calls runParser : String -> Grammar (TokenData Token) e ty -> Either ParseError ty from Idris2/src/Parser/Support.idr
repl : {auto c : Ref Ctxt Defs} ->
{auto m : Ref MD Metadata} ->
{auto u : Ref UST UState} ->
Core ()
repl
= do coreLift (putStr "Yaffle> ")
inp <- coreLift getLine
case runParser inp command of
Left err => do coreLift (printLn err)
repl
Right cmd =>
do if !(processCatch cmd)
then repl
else pure () |
It also uses 'command' from Idris2/blob/master/src/TTImp/Parser.idr.
-- TTImp REPL commands
export
command : Rule ImpREPL
command
= do symbol ":"; exactIdent "t"
tm <- expr "(repl)" init
pure (Check tm)
<|> do symbol ":"; exactIdent "s"
n <- name
pure (ProofSearch n)
<|> do symbol ":"; exactIdent "es"
n <- name
pure (ExprSearch n)
<|> do symbol ":"; exactIdent "gd"
l <- intLit
n <- name
pure (GenerateDef (fromInteger l) n)
<|> do symbol ":"; exactIdent "missing"
n <- name
pure (Missing n)
<|> do symbol ":"; keyword "total"
n <- name
pure (CheckTotal n)
<|> do symbol ":"; exactIdent "di"
n <- name
pure (DebugInfo n)
<|> do symbol ":"; exactIdent "q"
pure Quit
<|> do tm <- expr "(repl)" init
pure (Eval tm) |
Grammar does a similar job in the parser as Recognise does in the lexer:
| Lexer | Parser |
|---|---|
data Recognise : (consumes : Bool) -> Type |
data Grammar : (tok : Type) ->
(consumes : Bool) -> Type -> Type |
Lexer : Type Lexer = Recognise True |
Rule : Type -> Type Rule ty = Grammar (TokenData Token) True ty |
TokenMap : (tokenType : Type) -> Type
TokenMap tokenType = List (Lexer, String
-> tokenType) |
