
The first stage is to compile the file into the 'PTerm' structure:

Modules
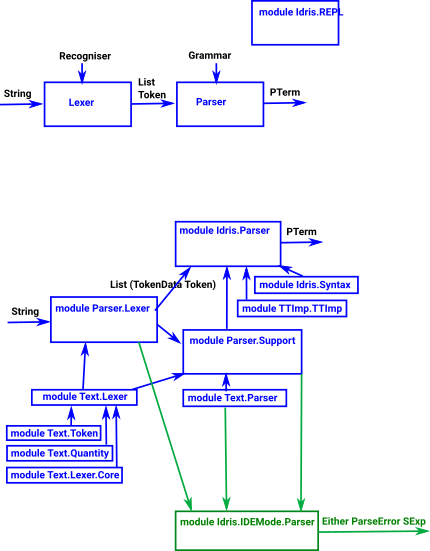
In the following diagram I have tried to put the lexer stuff to the left and the parser stuff to the right. Also the more general modules, that define the overall parser combinator structures at the bottom and the Idris language specific bits above (except the IDE mode at the bottom).
Files
| file | defines |
|---|---|
| Core2 | ||| A language of token recognisers.
||| @ consumes If `True`, this recogniser is guaranteed to consume at
||| least one character of input when it succeeds.
export
data Recognise : (consumes : Bool) -> Type where
Empty : Recognise False
Fail : Recognise c
Lookahead : (positive : Bool) -> Recognise c -> Recognise False
Pred : (Char -> Bool) -> Recognise True
SeqEat : Recognise True -> Inf (Recognise e) -> Recognise True
SeqEmpty : Recognise e1 -> Recognise e2 -> Recognise (e1 || e2)
Alt : Recognise e1 -> Recognise e2 -> Recognise (e1 && e2)
||| A mapping from lexers to the tokens they produce.
||| This is a list of pairs `(Lexer, String -> tokenType)`
||| For each Lexer in the list, if a substring in the input matches, run
||| the associated function to produce a token of type `tokenType`
public export
TokenMap : (tokenType : Type) -> Type
TokenMap tokenType = List (Lexer, String -> tokenType)
For REPL the following is different because there are no line numbers
but tokenData is built in to rules so need to adapt.
||| A token, and the line and column where it was in the input
public export
record TokenData a where
constructor MkToken
line : Int
col : Int
tok : a |
| Quantity2 | |
| Lexer2 | |
| ParserLexer2 | data Token = Ident String
| HoleIdent String
| Literal Integer
| StrLit String
| CharLit String
| DoubleLit Double
| Symbol String
| Keyword String
| Unrecognised String
| Comment String
| DocComment String
| CGDirective String
| EndInput |
| ParserCore2 | From Idris2/src/Text/Parser/Core.idr describes the grammar ||| Description of a language's grammar. The `tok` parameter is the type
||| of tokens, and the `consumes` flag is True if the language is
||| guaranteed to be non-empty - that is, successfully parsing the
||| language is guaranteed to consume some input.
export
data Grammar : (tok : Type) -> (consumes : Bool) -> Type -> Type where
Empty : (val : ty) -> Grammar tok False ty
Terminal : String -> (tok -> Maybe a) -> Grammar tok True a
NextIs : String -> (tok -> Bool) -> Grammar tok False tok
EOF : Grammar tok False ()
Fail : Bool -> String -> Grammar tok c ty
Commit : Grammar tok False ()
MustWork : Grammar tok c a -> Grammar tok c a
SeqEat : Grammar tok True a -> Inf (a -> Grammar tok c2 b) ->
Grammar tok True b
SeqEmpty : {c1, c2 : Bool} ->
Grammar tok c1 a -> (a -> Grammar tok c2 b) ->
Grammar tok (c1 || c2) b
Alt : {c1, c2 : Bool} ->
Grammar tok c1 ty -> Grammar tok c2 ty ->
Grammar tok (c1 && c2) ty |
| Parser2 | |
| Core2 | |
| Support2 | |
| IDEModeCommands2 | |
| IDEModeParser2 |
