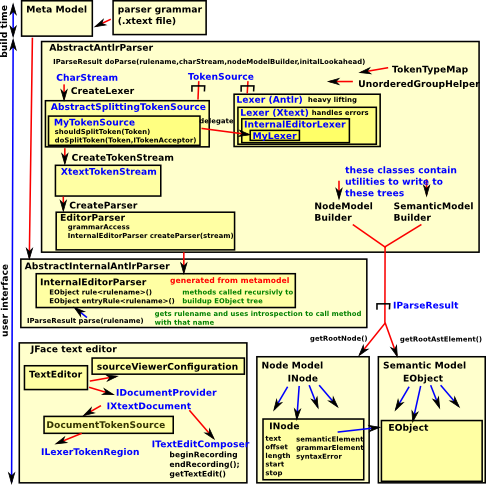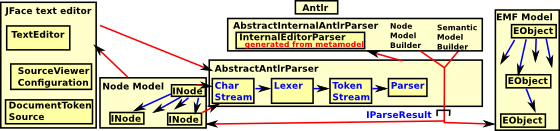
Xtext allows the lexer and/or the parser to be customised in certain ways. In order to do this we need to understand some of the internal workings of Xtext.
The above diagram is intended to give a top level picture of the process, there are 3 big external components involved here:
- The JFace text editor
- The Antlr parser
- The EMF model
Xtext is providing the glue linking together these components. There is a sequence of events going on here:
- Start with a character stream from Jface.
- Lexer
- Token stream
- Parser
The output of the Xtext parser is two separate tree structures:
- EMF model (semantic model) - used for validation and eventually code generation - I think this is the equivalent to the AST.
- Node Model - This is read by the Eclipse JFace text editor component to display and enter the text. Leaves in this tree are tokens which point to a chunk of text stream which must be contiguous and non-overlapping with other tokens.
The character stream is not altered by this sequence so, when text is referenced by tokens or nodes in the node model it can be referenced by indexes to the character stream.
Each token can refer to two separate text values:
- A start and end index into the text stream. This value will be used for the NodeModel.
- An explicit text value. This will be used for the EMF model.
Node Model
So each token can have two values. So if we take the macro example, the index for the macro will point to the macro name and the text value will contain the expansion of the macro.
PhantomToken
There is not an explicit mechanism for tokens which need to be used in the parser and will affect the EMF, but do not exist anywhere in the editor, such as the inserted curly brackets in the Python-like example above.
However we can cheat by making the start and stop indexes the same, this means that the token has little effect on the NodeModel. It is still important that the index values are contiguous with the tokens before and after it.
The best way to understand the indexes into the text stream is to think of the indexes as representing the spaces between the characters, not the characters, like this:
| Index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||||
| text stream: | { | { | { | a | } | } | } |
So the first character has index 0:1
The second 1:2 and so on.
This makes it easier to work out the indexes for composite nodes as well as leaf nodes. So, for example, the composite node holding the outer brackets is 0:7. The inner brackets are 2:5.
Customising Lexer
There are some more technical notes on page here and there are examples, for instance, Python-like whitespace block delineation and macroes here.
Diagram
Here is a diagrammatic representation of just part of what is going on here.