How much information a message contains depends on the extent to which it resolves uncertainty. This was explained by Dr Claude E Shannon of Bell Research Laboratories
What is Information? How do you measure how much information a message contains? Information theory, or communication theory, tries to answer these questions.
What is Communication?
The problem that Shannon was trying to solve was about transmitting messages through various channels: telephone, television, radio, and so on. All transmission channels have one drawback: They tend to partly change or corrupt the message being transmitted due to accidental errors or random signals that get mixed up with the intentional signals. This corrupting factor is generically called noise, whether it is actual noise on a radio or telephone, garbled telegraphic signals, or flicker on a TV. Shannon's specific concern was: What, if anything, can you do to counteract the effect of noise and transmit messages as faithfully as possible?
This leads to the question of how you measure information. You must be able to measure the information being sent and the information being received, so that you can compare them and see how much has been lost due to noise interference.
The basic structure of communication, as defined in Shannon and Weaver's book, breaks down into what happens at the transmitting end) and what happens at the receiving end. All information to be communicated is represented in some suitable code and sent over a transmission channel. At the receiving end, the information is received and decoded. During transmission, noise becomes mixed up with the actual signals being sent from the information source.
This concept of communication is broad enough to cover the process of storing information for later use, whether on paper, on disk, or in computer memory. The only difference between this process and more immediate communication is the delay, the indefinite amount of time between when the information is coded and placed in the "channel" and when it is received and decoded.
Bits of Information
Information is measured in bits in the same way as data used in a computer. For information theory the definition of bits is different. In information theory the information content depends, not just on the message itself, but also on the the receiver of the information and what they know already.
| Bits | Data | Information |
|---|---|---|
| unit: | bit (repbit) | bit (infobit) |
| must be an integer | positive real number (can have fractions of a bit) | |
| depends on: | number of bits in a message. | the extent to which it resolves uncertainty |
So here we have a situation with uncertainty, there are 8 possible messages that could be sent but we don't yet know which message will be sent. If we assume that each message is equally likely then its probability is 1/8 and its information content is log28= 3 bits. |
 |
||||||||||||||||
| We can see how these messages could be encoded using 3 bits, for instance, using the table here. |
|
||||||||||||||||
| Here this uncertainty has been resolved, when one of the messages is sent (in this case message 5). |  |
So, in information theory the information content of a message depends, not on the message itself, but on the uncertainty it resolved.
The above example was chosen to have a whole number of bits to show its similarities to bits in computing. However, in general, information does not always have a whole number of bits. For instance, if there were 6 possible message (say outcome of dice throw) then the information would be log26 which is not a whole number.
The above examples all assume equal probabilities for all messages, but this is not necessarily the case, we can decrease the uncertainty and therefore the information content of the messages if we know more about the probability of each message.
The extreme case of this is when we already know something, then the probability of such a message is 1 (that is 100% certain) then its information content is zero.
| Number of equally likely messages | Probability | Information Content |
|---|---|---|
| 0 | ||
| 1 | 1 | log21=0 |
| 2 | 0.5 | log22=1 |
| 3 | 0.333 | log23=1.5849625007 |
| 4 | 0.25 | log24=2 |
| 5 | 0.2 | log25= 2.3219280949 |
| 6 | 0.166 | log26=2.5849625007 |
| In general, if we know the probability of a message is 'p', then its information content will be: | log2(1/p) |
So why do we have this log2 function in the defintion of information? One advantage of this is that, in certain cases, it makes the information content correspond to the number of 'bits' as used in computing. The other advantage is that, if we have two independant messages, then the total information content is the sum of the individal inforamation contents, rather than taking a product.
Combining Messages
If we have more than one message how can we combine them? If the messages are independant, that is they are about different subjects, then we can add the information content of the original messages to give the total information.
| information content | ||
|---|---|---|
| message 1 | p1 | log2(1/p1) |
| message 2 | p2 | log2(1/p2) |
| message 1 or message 2 | log2(1/p1) + log2(1/p2) | |
| message 1 and message 2 | p1×p2 |
| To illustrate this, imagine that there are 4 equally likely messages: a,b,c and d so this message contains 2 bits of information. There is also another 4 equally likely messages: 1,2,3 and 4 so this also contains 2 bits. If we recieve both messages, this can distinguish between 16 outcomes which is 2+2 = 4 bits. | 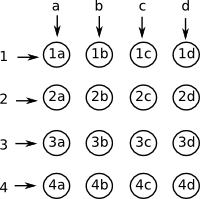 |
Postulates of Information Theory
- The more probable a message is, the less information it conveys.
- How much information a message contains depends on the extent to which it resolves uncertainty.
- A message is not significant by itself; it is significant in the context of all the other possible messages that could have been sent.
- When a message tells you something that you already know, the message conveys no information; there was no other possible message.
- "The significant aspect is that the actual message is one selected from a set of possible messages" (Shannon and Weaver).
- The greater the number of possible messages, the greater the amount of information conveyed.
Entropy
An alternative name that Shannon gave to the average amount of information is entropy, a term from thermodynamics. One interpretation of the amount of entropy in a physical system concerns the degree of uncertainty about which of many possible states of the system is actually realised at different stages. Shannon chose this name because of the analogy between realising one of many possible states and choosing one of many possible messages, and also because the mathematical equations for calculating thermodynamic entropy and average quantity of information were similar.
